



{{item.videoDuration}}
{{item.title}}
{{item.text}}

{{item.videoDuration}}
{{item.text}}
In recent years, chaos engineering has often been misunderstood as a way to intentionally cause failures in production systems, leading many companies to avoid implementing it. However, the true objective of chaos engineering is not to break production systems.
Instead, chaos engineering provides a valuable tool for teams to gain valuable insights into their workloads. It can be seen as a tool to find resilience gaps in existing workloads. By conducting controlled chaos experiments that are based on real-world hypotheses, teams can better understand the impact of potential failures.
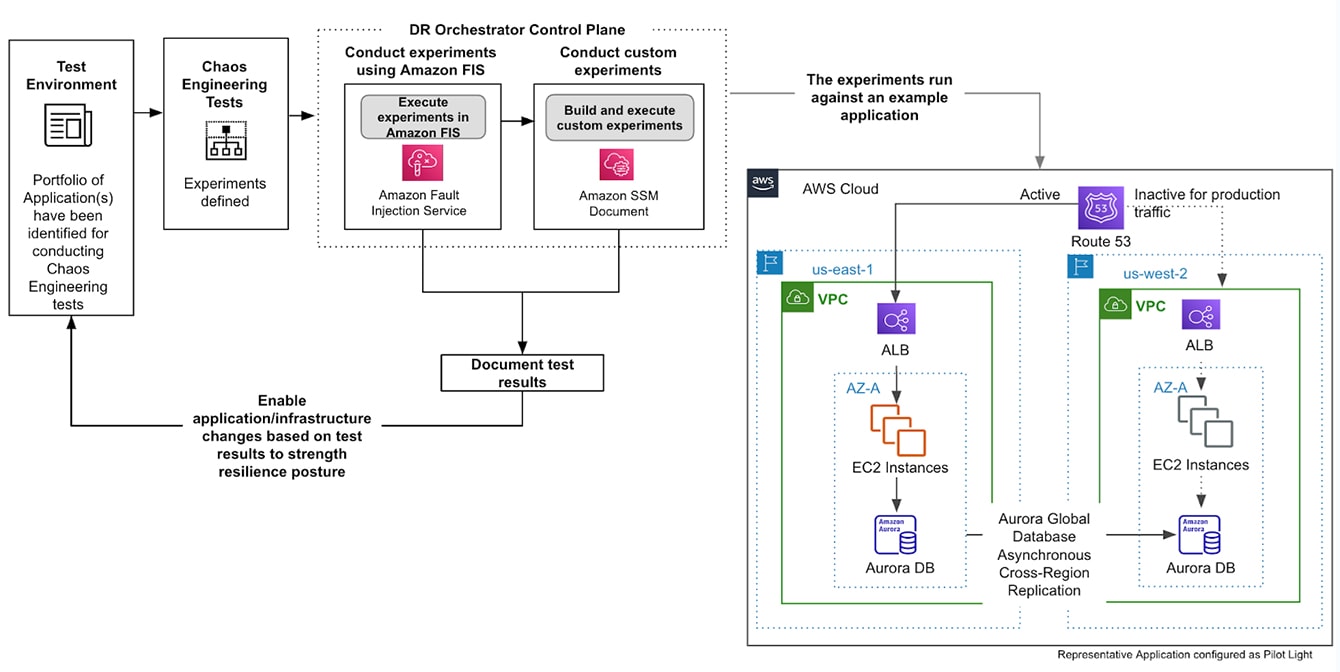
Our disaster recovery orchestrator framework allows you to run controlled chaos engineering tests to find resilience gaps in your existing workloads.
The framework serves as a consolidated platform that is capable of two integrations:
| AWS service | Sample chaos engineering experiments | Enablement method |
| Amazon Aurora | Simulate network latency between Aurora instances Introduce failures in Aurora replica instances Test the impact of increased load on Aurora read and write capacity |
Disaster recovery orchestrator framework |
| Amazon Kinesis | Simulate increased data ingestion rate to test the scalability of Kinesis streams | Disaster recovery orchestrator framework |
| Amazon EC2 | Test Spot Instance interruptions | Amazon Fault Injection Service (FIS) |
| Amazon DynamoDB | Denies traffic to and from the regional endpoint for DynamoDB in the current region | Amazon Fault Injection Service (FIS) |
Organizations are seeking ways to conduct chaos engineering experiments regularly using their existing deployment pipelines. This gives you the ability to find resilience gaps in existing workloads and document the risks in your application. Running the chaos engineering tests within your pipelines also allows you to assess your operational practices. It allows you to assess that your monitoring and alerting processes are in place to inform you about scenarios that could cause an outage in your application.
If you would like help in addressing these questions or want to explore any of the focus areas listed above, reach out to us.
{{item.text}}
{{item.text}}





