




"I see SLMs becoming major players in the near future. Their cost and energy efficiency, together with the ability to provide more domain-specific and pertinent answers, are more in line with our high expectations on domain expertise. Ultimately, LLMs may actually become routers or SLM aggregators able to package the best answer from more specialised models."
Introduction
Over the past few years, the rapid evolution of GenAI, particularly Large Language Models (LLMs), has significantly changed how we interact with technology, delivering transformative value to organisations across all sectors.
In fact, since the release of ChatGPT in November 2022, our fascination with AI has surged, leading to widespread exploration of concepts, such as LLMs and their implications. 2023 was hailed as the breakout year for GenAI, as evidenced by the rapidly increasing interest in LLMs and their potential to solve challenging problems.
New sets of LLMs are now being introduced every week with new capabilities, trained on vast amounts of text to understand existing content and generate original content. As a result they possess an unparalleled depth and breadth of knowledge and are exceptional in performance across various domains and tasks. GenAI has emerged as an indispensable tool, offering a seemingly magical shortcut for tasks spanning content creation to project management, catering to professionals across diverse sectors.
However, this paradigm shift comes at a cost – both literal and figurative. The high cost of deploying LLMs, especially for less commonly supported languages, such as Arabic, presents a barrier for many organisations.
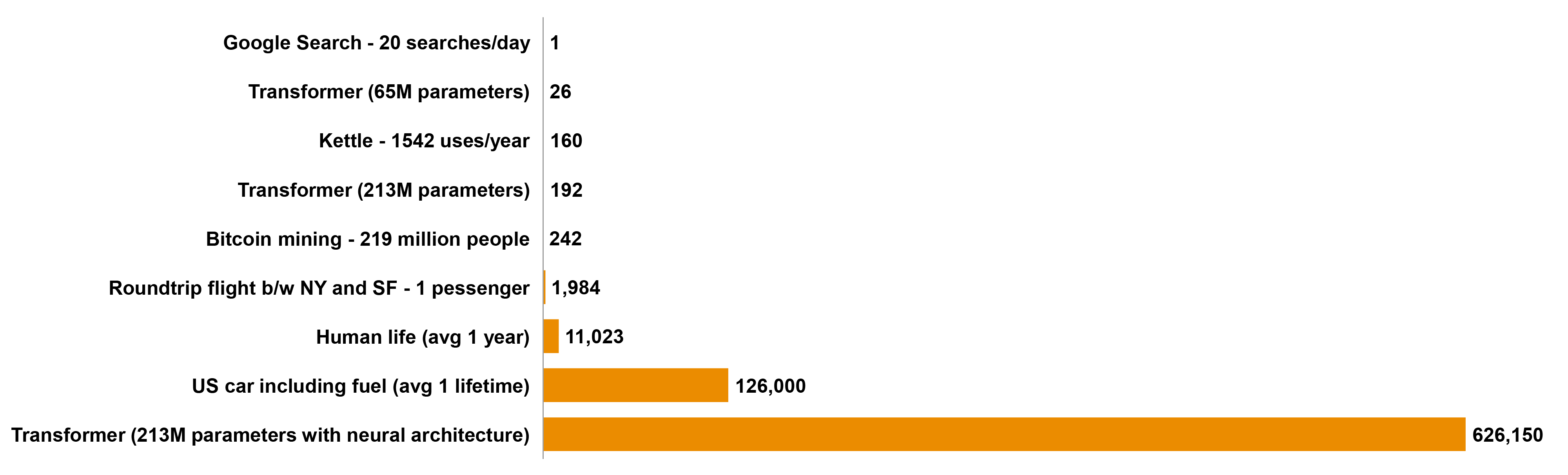
The estimated dynamic computing cost in the case of GPT-3 is equivalent to two or three full Boeing 767s flying round-trip from New York to San Francisco; the current provision of consumer LLMs may be more like a Boeing 767 carrying one passenger at a time on that same journey7.
In response to these challenges, the open-source community has collaborated to democratise access to GenAI technology by releasing smaller open-source alternatives, known as Small Language Models (SLMs).
SLMs are a lightweight GenAI model. The term “small” in this context refers to the size of the model’s neural network and the number of parameters it uses. As organisations grapple with the escalating complexity and cost associated with LLM adoption, SLMs offer an attractive solution, promising efficiency without compromising on performance.
In this article, we explore the evolving landscape of SLMs, delving into their respective strengths, weaknesses and the overarching implications for industries at large. By examining the details of this transformative technology, we aim to provide readers with the insights and knowledge necessary to navigate this dynamic field and harness the full potential of GenAI in driving innovation and fostering digital transformation.
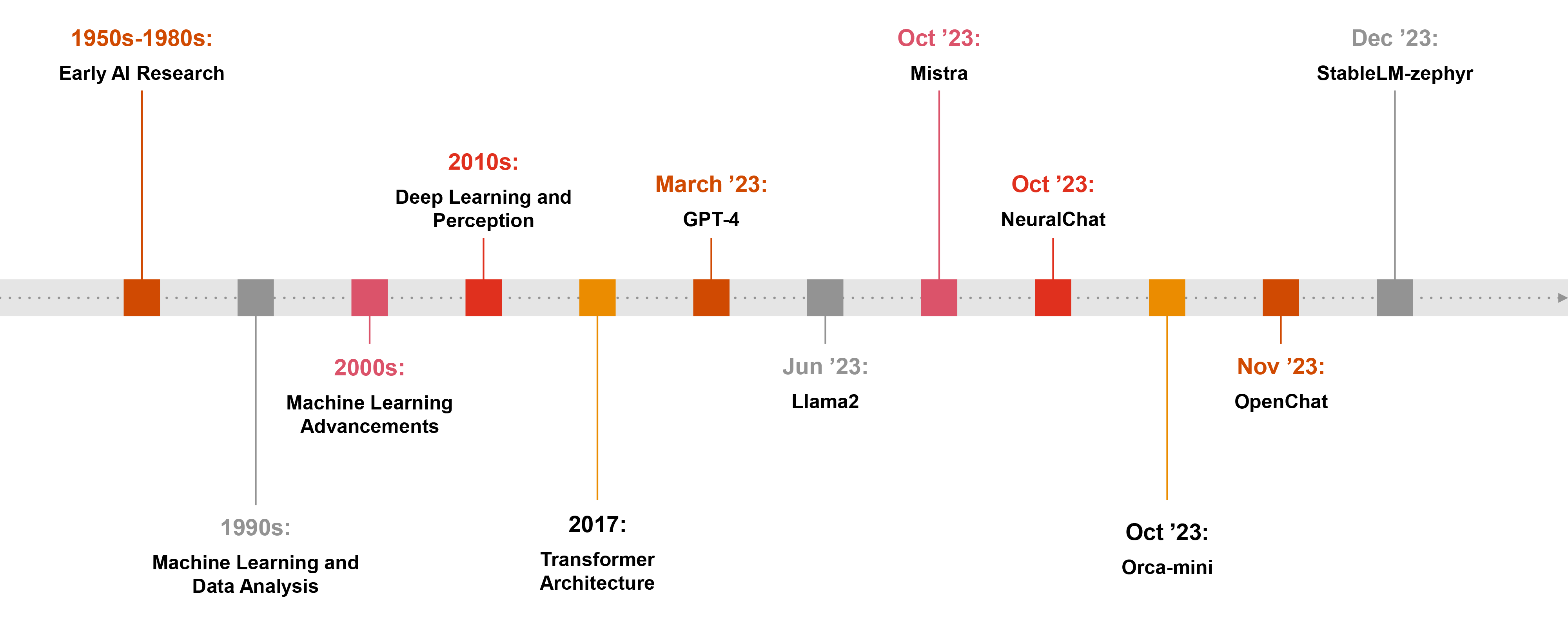
Comparison methodology
LLMs are trained on vast text datasets that enable capabilities of generating extensive text, summarising documents, providing translation for different languages and replying to complex inquiries. Conversely, SLMs possess the same capabilities; however, they are notably smaller in size, yet equally advantageous when it comes to cost, efficiency and customisability.
To make an informed decision between LLMs and SLMs, we must perform a comparative analysis, benchmarking and evaluation of the performance of both across various criteria.
- Efficiency
- Capabilities
- Customisation
- Computation
- Regulatory and policy frameworks
- Sustainability
Efficiency
As the name suggests, LLMs are considerably large-scale models, typically containing hundreds of millions or even billions of parameters with a deep architecture comprising multiple layers.
SLMs have fewer parameters, simpler architecture and fewer layers, which makes them more computation-efficient than massive loads of LLMs. Due to SLMs' reduced model size, they also require less storage for weights and less memory for processing.
Capabilities
LLMs can capture complex linguistic patterns and generate coherent, contextually relevant text. They show adeptness in tasks such as text generation, completion, language translation and sentiment analysis.
On the other hand, SLMs can still be effective and can produce natural processing tasks that are simpler but customised.
Customisation
SLMs are readily adaptable to specialised applications and less complex use cases. With faster iteration and training cycles, they allow for further experimentation and customisation of their models to specific data types. They can, therefore, be used to address specific gaps in industries that are not adequately served by AI, improving outcomes with tailored language assistance.
However, this kind of customisation process becomes increasingly challenging for LLMs. The sheer size and intricacy of these models require more computational resources and time to fine-tune or adapt them to different tasks or domains.
Computation
LLMs, because of their inherent architecture, require more computation resources such as Graphical Processing Units (GPUs) to load all layers and process them in parallel during the training and serving process. Due to the large number of parameters involved, processing more complex computations increases the overall training time and requires more GPUs, which results in larger computation overheads. This cycle of hardware turnover contributes to electronic waste, as outdated equipment is discarded or recycled. Based on one study, electricity requirements for running ChatGPT over a monthly period is between 1 and 23 million kilowatt-hours (kWh), which corresponds to the emissions of 175,000 residents of Denmark7.
Alternatively, SLMs are smaller in size and require less GPU memory due to their reduced computational demand, and can even fit-in CPUs for inference. This also helps during the fine-tuning of the models.
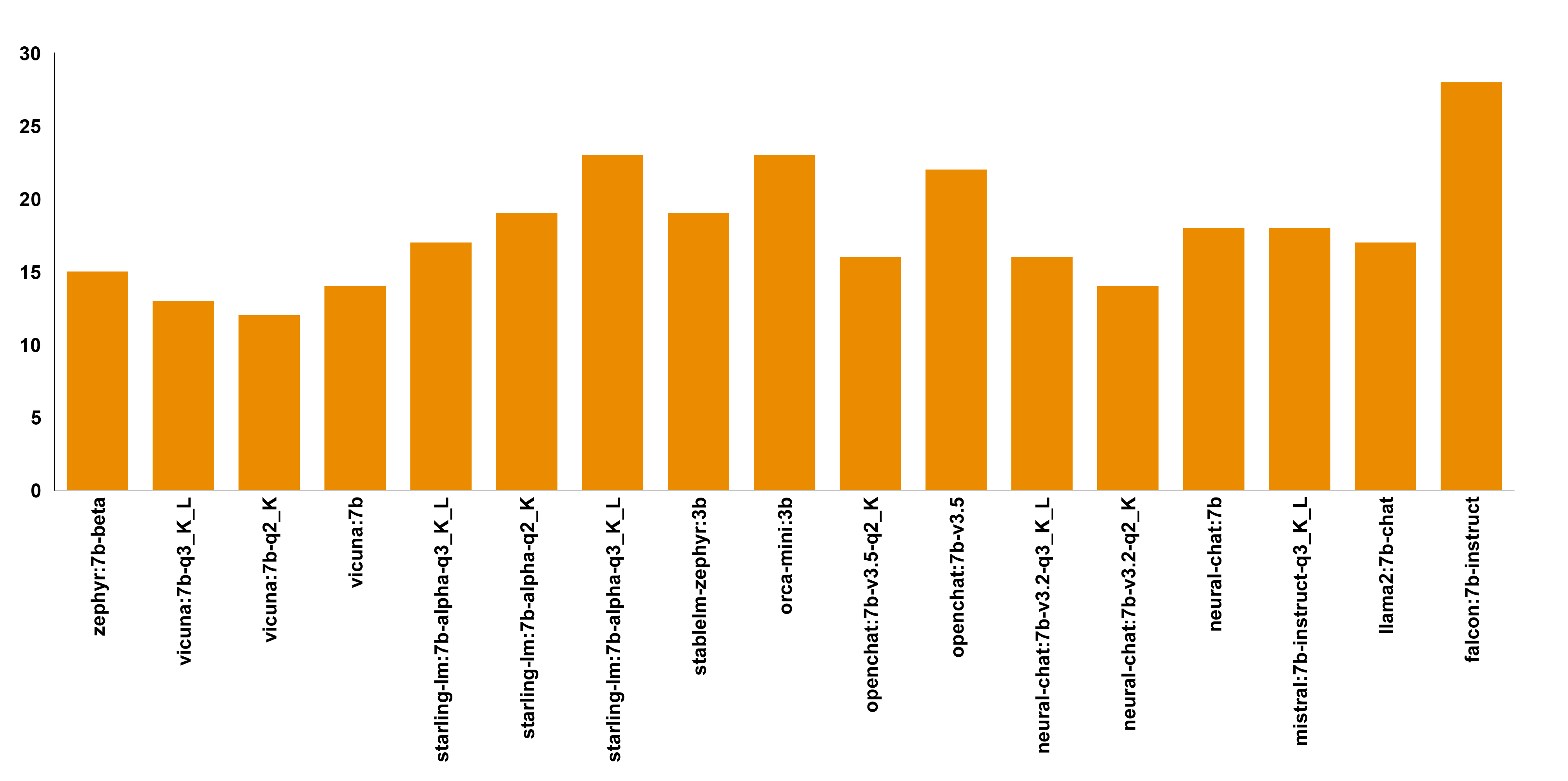
Regulatory and policy frameworks
LLMs frequently demand extensive datasets for training, leading to substantial concerns regarding data privacy and protection, and hallucination. This poses challenges in meeting compliance standards such as General Data Protection Regulation (GDPR) and National Data Management Office (NDMO).
Conversely, SLMs typically operate on a smaller scale and necessitate less data for training, thus making regulatory adherence less challenging compared to LLMs.
Sustainability
LLMs have a huge impact on the environment, such as energy consumption, carbon footprint, electronic waste, and cloud computing infrastructure. This hardware consumes a significant amount of energy during training, which contributes to the carbon emission and has an impact on the environment. Also, there is an additional requirement of managing the electronic waste to mitigate its environmental impact. Another study states there is an approximately 1,287,000kWh energy or 552 tonnes of CO2 required to train the model behind the original ChatGPT8.
SLMs do not require high-end systems to train and can use smaller GPUs for training and CPUs for serving to meet business needs. This approach can possibly lead to innovations and best practices for mitigating the environmental impact.
Implementation approaches
The road ahead for SLMs holds an immense promise in reshaping the landscape of GenAI and Natural Language Processing (NLP). Their advantages substantially put them as a viable approach to LLM adoption. There are many strategies to optimise model sizes and maximise their performance and efficiency even further, such as quantisation, sparsity/pruning, distillation and adaptation.
1. Quantisation
Quantisation is a technique to reduce the model’s size by lowering the precision of the model's weights and activations. Hence, the compressed model uses less memory, requires less storage space, and performs faster. There are two types of LLM quantisation: Post-Training Quantisation (PTQ) and Quantisation-Aware Training (QAT). The main difference between the two types is “when” the quantisation process takes place. PTQ optimises the model “after” the model has been fully trained. While it is simpler and faster, some accuracy is lost in the process. QAT integrates quantisation during the training process. This is more computationally intensive and requires additional training time but results in a higher accuracy since it learns to adapt to the lower precision representation.
2. Sparsity/pruning
This optimisation method is usually paired with quantisation to opt for maximum efficiency. The technique involves trimming non-essential parameters, which are near zero, and replacing them with zeros. By doing so, the matrix occupies less space compared to a fully condensed version while retaining the significant parameters unaffected, thus preserving the model’s accuracy.
3. Distillation
It is like a master transferring its knowledge to their student. The distillation optimisation technique moves knowledge from a LLM to a smaller model that has a simpler architecture. Take, for example, BERT, one of the most renowned transformers-based deep learning models. DistilBERT shrinks the BERT model by 40% while maintaining 97% of its language-understanding abilities, all at a speed that’s 60% faster.
4. Adaptation
There are a couple of common methods to adapt LLMs and SLMs downstream for a specific task or use case. These methods depend on the nature of your dataset. If your data is structured for training, you may opt for a fine-tuning approach. For instance, Parameter-Efficient Fine-Tuning (PEFT) is a technique used to fine-tune SLMs to specific tasks by training only a small number of additional parameters. PEFT has become a popular approach as it is significantly lower in computational costs and storage requirements while maintaining comparable performance to full fine-tuning. On the other hand, if the data is unstructured, then Retrieval-Augmented Generation (RAG) framework boosts the model’s accuracy by performing indexing and semantic search. RAG ensures that the model’s responses are confined to relevant search results, thus generating accurate outputs.
Small size, large advantages
LLMs and SLMs offer different benefits and advantages. They both have their unique strengths and limitations.
Overall, SLMs deliver strong ROI through cost savings from reduced computational needs and faster deployment, improved performance due to task-specific customisation, and enhanced business applications such as streamlined customer service and efficient content generation. These factors combine to lower expenses, increase productivity, and unlock new revenue opportunities.
- Efficiency
- Ease of interpretability
- Customisation and adaptability
- Privacy and security
- Lower energy consumption
- Reduced carbon footprint
- Democratisation
- Ethical AI
Efficiency
Due to their lightweight nature, SLMs enable faster inference times. Faster response time makes it suitable for applications like Chatbots and IoT devices. SLMs result in reduced power consumption and a lower demand for hardware, promoting efficient resource use and cost-effectiveness.
Ease of interpretability
A simpler design and domain-focused model make SLMs more interpretable then LLMs, making it easy for developers to understand and introduce changes and train the model incrementally.
Customisation and adaptability
SLMs can be fine-tuned for specific business cases, allowing developers to optimise performance based on specific requirements of the business, which can be tailored to niche applications and leads to high accuracy.
Privacy and security
SLMs can pose lower privacy and security risks because they use fewer parameters and can be trained on client-specific data.
Lower energy consumption
With fewer parameters and a less complex architecture, SLMs can run on simple CPUs – rather than GPUs – which makes them well suited for deployment in resource-constrained environments.
Reduced carbon footprint
SLMs are considered energy-efficient solutions that minimise the environmental footprint. Lower energy consumption also means less electricity is required to power servers and data centres where these models are deployed and trained.
Democratisation
Due to fewer parameters being used, simpler design principles and domain-focused models, SLMs are more accessible to a wide range of users and empowering people to leverage these modes for innovation and research.
Ethical AI
Due to the domain-specific nature of these models, SLMs can be used to detect biases in data by analysing training data. Using SLMs, users can have access to the underlying reasoning behind an AI decision, which can help identify any discrimination patterns and implement corrective measures.
A future of potential and stewardship
The advent of SLMs marks a pivotal shift in the landscape of AI and natural language processing. These models, characterised by their efficiency, adaptability and domain-specific capabilities, are poised to democratise access to AI technologies, making them readily available for a wider range of applications and industries.
SLMs have demonstrated remarkable potential in use cases such as chatbots, real-time data analysis and customer service, offering cost-effective and scalable solutions. Their ability to be fine-tuned for specific tasks and domains ensures that they can be tailored to meet the unique needs of various organisations, making them invaluable tools for enhancing productivity, automating processes and improving decision-making.
While SLMs represent a significant step forward, it is important to acknowledge the ongoing research and development in this field. As the technology continues to mature, we can anticipate further improvements in efficiency, accuracy and capabilities, paving the way for even more innovative and impactful applications.
In the years to come, SLMs are poised to play an increasingly vital role in shaping the future of AI. Their accessibility, versatility and potential for customisation make them a compelling choice for businesses and organisations seeking to harness the power of AI to drive growth, innovation and success. As research and development continue to push the boundaries of what is possible, we can look forward to a future where SLMs become ubiquitous, empowering individuals and organisations alike to achieve their goals through the transformative power of AI.
References
1.Large Language Models (LLMs)
3. Language Model Quantisation Explained
4. Mastering LLM Techniques: Inference Optimisation
5. Mastering LLM Optimisation With These 5 Essential Techniques
6. A Guide to Quantisation in LLMs
7. Environmental Impact of Large Language Models
8. WHEN SMALL IS BEAUTIFUL: HOW SMALL LANGUAGE MODELS (SLM) COULD HELP DEMOCRATISE AI
9. Energy and Policy Considerations for Deep Learning in NLP





