

フィーチャーエンジニアリングとは?ーテクノロジー最前線 データアナリティクス&AI編(2)
2022-05-10
テクノロジーの最前線を紹介するコラムの第2回。データサイエンティストにとって予測精度を高めるための基本かつ必須の手法の一つであるデータエンジニアリング(特徴量エンジニアリング)について説明します。
今日、多くの場合、データサイエンティストは、同じようなモデルとプログラミングライブラリーを利用しています。これにより、同じデータを使用するとどうしても同じようなアウトプットになってしまいます。このため、現在データサイエンティストが差別化を図るには、フィーチャーエンジニアリング(特徴量エンジニアリング)への取り組みを進める必要があるのです。
フィーチャーエンジニアリングは、モデルのパフォーマンスを高めるため、オリジナルデータを新しい変数(フィーチャー:特徴量)に変換することです。このテクニックは、ディープラーニングやマシンラーニングから伝統的な計量経済学のモデルに至るまで、あらゆるモデルで活用できます。
この記事では、2つのタイプのフィーチャーエンジニアリングをご紹介します。
- フィーチャートランスフォーメーション: 既存の特徴変数の変換
- フィーチャークリエーション: 既存の特徴変数から新しい特徴変数を生成
フィーチャートランスフォーメーション
筆者はこれまでに実施したプロジェクトにおいて、気温の変化から電力需要を予測するため、気温を説明変数、日本の電力需要を被説明変数とする線形モデル(ARIMA)を使用しました。まずは、2019年の電力需要と東京の気温の毎日の平均値を取得し、この2つの変数に関係があるかを確認するため、グラフにしてみました(図1)。
図1 電力需要 vs 気温 時系列データ

出所: JPEX(日本卸電力取引所)、OCCTO(電力広域的運営推進機関)のデータをもとにPwCで作成
図1からは、電力需要と気温の間の明確な関係性を見いだすことができません。続いて、本当に2つの変数に全く関係性がないのか判断するため、データを散布図にプロットして確認してみました(図2)。この図からは、電力需要と気温との間に二次関数グラフ状の線的な関係性が見て取れます。しかし、これらの変数を線形モデルに当てはめた場合、決定係数(R²)は0.01以下となりました。この数字は変数の関係性が線形モデルでは説明できないことを意味しています。
図2 電力需要 vs 気温 散布図
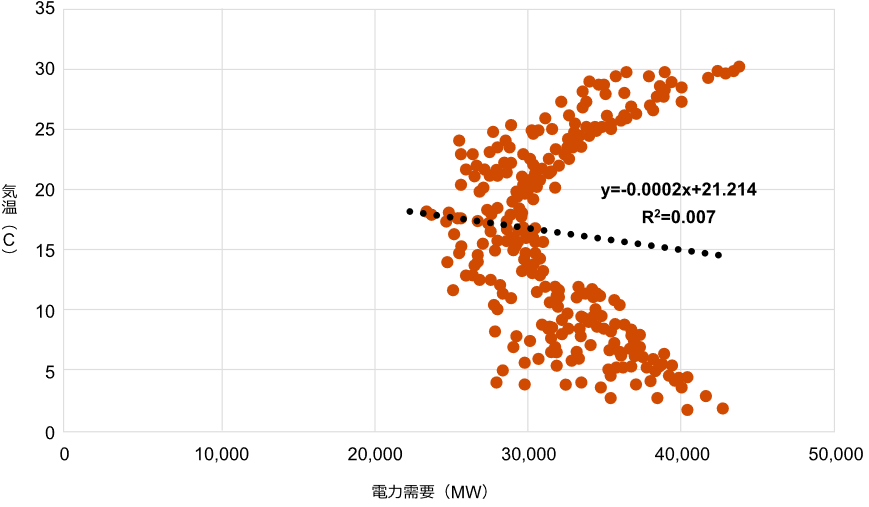
出所: JPEX(日本卸電力取引所)、OCCTO(電力広域的運営推進機関)のデータをもとにPwCで作成
この問題を解決するため、私たちはフィーチャーエンジニアリングを使用しました。気温のデータを新しい特徴量(New Feature)に変換することにしたのです。
新しい特徴量=(気温-17)2
このように特徴量に変換することにより、図2のような線形モデルに合致しないデータを線形モデルで利用できる形に再生することができます。この特徴量は、気温が電力需要に与える影響が最も少なくなる摂氏17度と実際の気温との差の大きさを表しています。
このデータを使用した新しい散布図では、電力需要との間に明確な線的関係が見てとれます(図3)。さらに、時系列のグラフにしてみると、2つの数値が明らかに似た動きをしていることが分かります(図4)。
図3 電力需要 vs 新しい特徴量 散布図
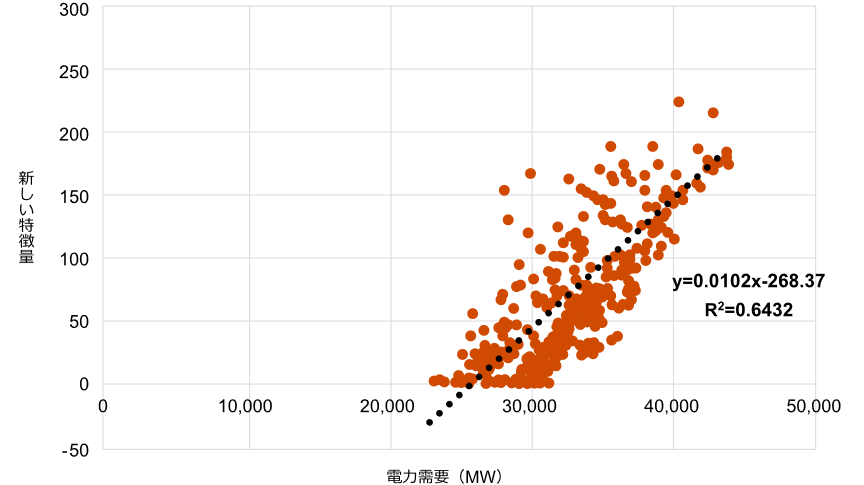
出所: JPEX(日本卸電力取引所)、OCCTO(電力広域的運営推進機関)のデータをもとにPwCで作成
図4 電力需要 vs 新しい特徴量 時系列グラフ

出所: JPEX(日本卸電力取引所)、OCCTO(電力広域的運営推進機関)のデータをもとにPwCで作成
図3、図4における発見を踏まえ、私たちのモデルには、実際の気温のデータではなく、新しい特徴量を取り入れました。このモデルを実際に3年以上使用していますが、99.5%以上の正確性を保っています。これは主にフィーチャートランスフォーメーションの成果によるものです。
フィーチャークリエーション
別のプロジェクトでは、日時(説明変数)と電力需要(被説明変数)というたった2つの変数しか使用できないという制約の中で、外国の電力需要を予測するよう依頼されました。このシナリオではXGBoostモデルを使用しましたが、XGBoostモデルでは日付のフォーマットが使用できなかったので、これが最初の障壁となりました。この壁を乗り越えるため、元データをモデルで使用できる形に変換する必要がありました。このため、日付データを新しい特徴量に作り変えたのです。
当初、下表のように、各日時と、その日時に対応する電力需要のデータしかなかったため、時間が電力需要に与える影響をモデルが学習するには不十分でした。

(データはダミー)
一方、元データを新しい特徴量に変換した後には、電力需要を説明する変数は以下のように9つとなりました。もし上述の単純なデータのみからなる自己回帰モデルを使用していたら、このモデルは有用でないどころか、モデルを混乱させてしまっていたかもしれません。

(データはダミー)
結果として、このモデルはテストデータから十分に満足できる結果を導くことができました。このケースでは、新しい特徴量を作り出すことによって、モデル自体を修正する手間をかけることなく、モデルを使用することができました。
このようなフィーチャーエンジニアリングによってモデルのパフォーマンスを高めることで、データサイエンティストはより高精度な予測を実現できるのです。
執筆者

A. Medioni
AI Labとフォレンジックスのデータアナリティクスチームのマネージャーをしています。以前は財務モデリングチームに属しており、エネルギー、公共事業、コンシューマー&リテール、フォレンジックスなどが専門分野です。電力市場分析ツールPower Market Analyticsの開発チームやフレンチデスクの主要メンバーでもあります
PwC Japanグループでは、データアナリティクス領域でご活躍いただける方を募集しています。本記事に関連する求人情報は以下ページよりご覧ください。
|
テクノロジー最前線―先端技術とエンジニアリングによる社会とビジネスの課題解決に向けて
データアナリティクス&AI編
(1):テック人材の採用と維持における企業の課題
(2):フィーチャーエンジニアリングとは?
(3):SNSを活用したコロナ禍における人々の心理的変化の洞察
(4):自然言語処理(NLP)の基礎
(5):今、データサイエンティストに求められるスキルは何か?データサイエンティスト求人動向分析
(6):コロナ禍における人流および不動産地価変化による実体経済への影響
(7):「匠」の減少―技能継承におけるAI活用の道しるべ
(8):開示された企業情報におけるESGリスクと財務インパクトの関係性の特定
(9):ビッグデータ分析で特に重要な「非構造化データ」における「コンピュータービジョン(画像解析)」とは
(10):自然言語処理・数理最適化による効率的なリスキリングの支援
(11):スポーツアナリティクスの黎明 サッカーにおけるデータ分析
(12):AIを活用した価格設定支援モデルの検討―外部環境変化に即座に対応可能な次世代型プライシング
(13):MLOps実現に向けて抑えるべきポイントー最前線
(14):合成データにより加速するデータ利活用
エマージングテクノロジー編
(1):ブロックチェーン技術の成熟度モデルとステーブルコインの最新動向について
(2):3次元空間情報の研究施設「Technology Laboratory」のデジタルツイン構築とデータの管理方法
(3):3次元空間情報の研究施設「Technology Laboratory」における共通ID「空間ID」と自律移動体の測位技術
(4):G7群馬高崎デジタル・技術大臣会合における空間IDによるドローン運航管理
エンジニアリング編
(1):COVID‐19パンデミック下のオンプレミス環境におけるMLOpsプラクティス
(2):機械学習を用いたデータ分析
(3):AWSで構築したIoTプラットフォームのPoC環境をGCPに移行する方法
(4):テクノロジーの社会実装を高速に検証するPwCの独自手法「Social Implementation Sprint Service」-テクノロジー最前線
(5):自動車業界におけるデジタルコックピットの擬人化とインパクト
(6):成熟度の高いバーチャルリアリティ(VR)システム構築理論の紹介
(7):イノベーションの実現を加速する「BXT Works」とは
(8):Power Platformの承認機能、AI Builderを活用して業務アプリを開発する方
(9):社会課題の解決をもたらす先端テクノロジーとディサビリティ インクルージョンの可能性


